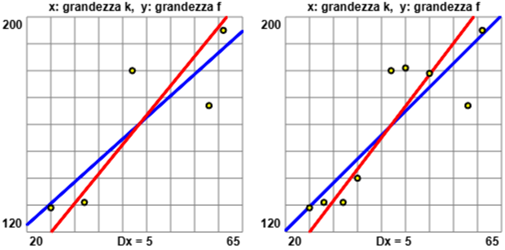
Nello studio di un fenomeno fotoelettrico si vuole sperimentare se la
relazione tra due grandezze fisiche k e f è di tipo lineare,
ossia del tipo f = A·k + B, con A e B costanti. Si ottengono, con misurazioni ad alta
sensibilità, i valori seguenti:
K: 25, 32, 42, 58, 61; F: 129,131,180,167,195
Si ottiene il coefficiente di correlazione 0.8562632897645447 (che arrotondo a 0.856), molto vicino ad 1, e si tracciano
le rette di regressione sia considerando f in funzione di k che viceversa,
ottenendo il grafico sotto a sinistra. Aggiungendo altri rilevamenti
si ottengono i valori seguenti:
K1: 25, 28, 32, 35, 42, 45, 50, 58, 61; F1: 129,131,131,140,180,181,179,167,195
ottenendo il coefficiente di correlazione 0.8711982325065797 (che arrotondo a 0.871) e il grafico sotto a destra.
Aver effettuato altri esperimenti è stato utile per ipotizzare l'esistenza di una relazione lineare tra k e f?
Apparentemente la situazione non è molto migliorata. Ma, intuitivamente,
il fatto di aver operato su più dati dovrebbe darci una maggiore sicurezza. Del resto
se avessi avuto solo gli esiti di una coppia di esperimenti, ad esempio
Il fatto è che il coefficiente di correlazione (vedi)
determinato su un campione (nel nostro caso le misure ad alta sensibilità effettuate)
non ha un valore "esatto", ma un intervallo di indeterminazione la cui ampiezza dipende anche
dalla quantità dei dati a disposizione. Al di là del modo in cui determinare
l'intervallo di indeterminazione, questo è un aspetto importante da tener presente.
La situazione è del tutto analoga al caso delle misure di una singola grandezza (vedi): se di una grandezza ho ottenuto le 7 misure ad alta sensibilità 7.3, 7.1, 7.2, 6.9, 7.2, 7.3 e 7.4 posso prendere come valore della grandezza il valor medio 7.2 ma devo associargli una precisione, che dipende da come sono distribuiti i dati e da quanti sono. Se a 7.2 associo come precisione σ ottengo 7.2±0.062 con la probabilità del 68%, se associo 2σ ottengo 7.2±0.123 con la probabilità del 95%, se associo 3σ ottengo 7.2±0.185 con la probabilità del 99.7%.
Il calcolo degli intervalli di indeterminazione per coppie di dati come quelle di questo quesito è più complesso, affrontabile solo in alcuni corsi universitari (ad esempio usando il programma R project). Osserviamo che nel caso dei dati K1 e F1 si otterrebbe l'intervallo [0.6,1] (ossia 0.8±0.2) con probabilità del 90%; nel caso di K e F si otterrebe una inderminazione più che doppia (in pratica non si potrebbe ottenere alcuna valutazione significativa della relazione tra k e f).
I grafici sono stati ottenuti con questi script: uno e due.
Ecco come usare in questo caso R project:
K = c(25, 32, 42, 58, 61); F = c(129,131,180,167,195) cor.test(K,F, conf.level = 0.90) Pearson's product-moment correlation data: K and F t = 2.8712, df = 3, p-value = 0.06399 alternative hypothesis: true correlation is not equal to 0 90 percent confidence interval: 0.1155630 0.9849879 sample estimates: cor 0.8562633 K1 = c( 25, 28, 32, 35, 42, 45, 50, 58, 61) F1 = c(129,131,131,140,180,181,179,167,195) cor.test(K1,F1, conf.level = 0.90) Pearson's product-moment correlation data: K1 and F1 t = 4.6951, df = 7, p-value = 0.002221 alternative hypothesis: true correlation is not equal to 0 90 percent confidence interval: 0.5826869 0.9646953 sample estimates: cor 0.8711982 cor.test(K1,F1, conf.level = 0.60) Pearson's product-moment correlation data: K1 and F1 t = 4.6951, df = 7, p-value = 0.002221 alternative hypothesis: true correlation is not equal to 0 60 percent confidence interval: 0.7592490 0.9330715 sample estimates: cor 0.8711982